NFS VM Cached Read Illustrated
This article illustrates how the virtual memory (VM) subsystem of the Linux kernel is able to cache files that are located on an NFS server.
Environment¶
In this small experiment we just need two Linux machines on a local network, where one acts as NFS server and the other one as NFS client. With a current Linux distribution like Fedora 26 you get NFSv4 if you don't do anything special.
The following results are from a 1 GBit ethernet network where the NFS client has 16 GB RAM and both machines run Fedora 26.
High-Level View¶
A simple way to read over the network from an NFS filesystem without yielding disk IO on the client is:
- empty the VM cache - e.g. rebooting the client and server
or via executing
free && sync && echo 3 > /proc/sys/vm/drop_caches && freeon both machines - on the client:
cata relatively large file from a NFS filesystem to/dev/null
The file should be large enough such that we can easily measure some metrics but small enough to fit into RAM.
In our environment the 4.2 GB backup copy of the John Woo movie 'The Killer' is well suited:
$ time cat The_Killer.iso > /dev/null
The zsh time builtin reports:
0.00s user 1.08s system 2% cpu 38.373 total
That means it took 38 seconds to transfer that 4.2 GiB file. This is
plausible because the resulting read rate of 113 MiB/s is close
to the wire speed (10^9/8/1024/1024) minus the expected protocol overhead.
Executing the read command
$ time cat The_Killer.iso > /dev/null
a second and third time is way faster:
0.00s user 0.57s system 99% cpu 0.578 total
0.00s user 0.44s system 98% cpu 0.447 total
Just half a second.
After clearing the VM cache with
# free && sync && echo 3 > /proc/sys/vm/drop_caches && free
where the final free reports
buff/cache
1871568
and reading the file just another time we are back at the initial timing:
0.02s user 1.26s system 3% cpu 38.551 total
A free then reports
buff/cache
6267676
This is plausible as well, i.e. (6267676-1871568)/1024/1024
is close to the 4.2 GB file size.
If we have a rough idea how the VM subsystem works with a local filsystem in a common OS kernel (like Linux) all this isn't surprising. One just might wonder how the kernel decides that it is safe to reuse the VM cache since the file could have changed on the server (e.g. locally or by another NFS client).
We can verify that the kernel is able to detect file changes by other parties via touching the file on the server, e.g.:
$ touch The_Killer.iso
After that, reading the file again on the client takes the initial amount of time (39 seconds).
Dstat¶
When running the dstat command on the client we can obtain a
more detailed picture. For example:
$ dstat -d -D total -g -n -N enp0s31f6 -r -c --vm
By default, dstat repeatedly averages over 1 second, i.e. it prints every
second a new line.
The dstat output during the first file read:
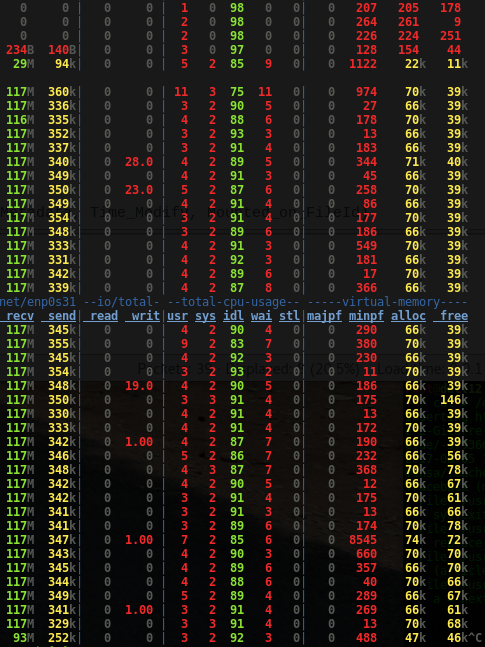
We can observe a few things in the listing:
- the network receive rate matches the computed read rate (modulo protocol overhead) and since reads need to be acknowledged the outgoing network traffic increases as well
- directly after starting the read the VM heavily allocates and
frees caches pages (in the order of
60 * 10^3pages or so)
The work the VM subsystem is doing is plausible. The system has a page size of 4 KiB and thus the amount of cache pages is sufficient to deal with the read rate.
The listing for the second read is much shorter:
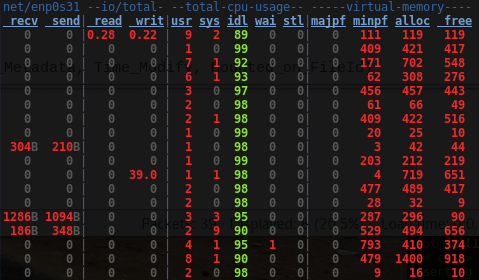
Here we don't see much network traffic, but we see a clear increase in traffic that could be explained by some NFS communication where the client inquires the server whether the file is outdated or not.
Also, as expected, the VM subsystem isn't busy with allocations and frees as before.
NFS Traffic¶
To get an idea how the NFS client detects file changes we can capture the network traffic and inspect with an analyzer like Wireshark.
In case directly capturing with Wireshark isn't an option, a simple alternative is to capture with tcpdump to a file and open that file later with wireshark, e.g.:
# tcpdump -i enp0s31f6 -s0 -w /var/tmp/nfs.dump
The NFS flow for the second file read is quite compact in the wireshark overview:
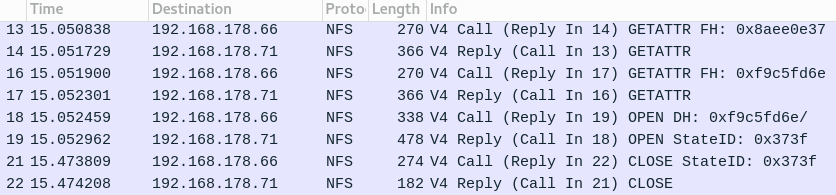
As expected, it is NFS version 4 and there are just a few query operations.
In detail the second GETATTR reply:
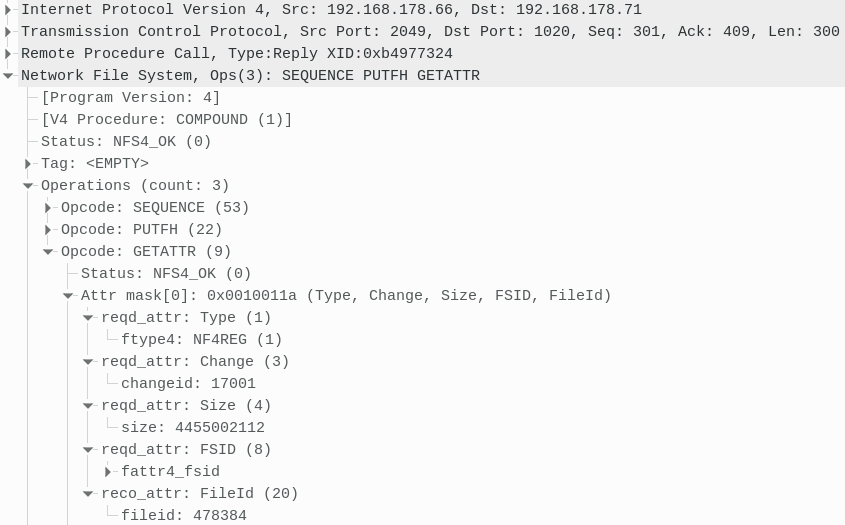
We observe that the server replies that the file is a regular
file (NF4REG) and reports its change-ID and file-ID.
The file-ID is conceptually similar to an inode and thus the NFS client can compare the change-ID with the one obtained from last time to decide if it can reuse the pages from the VM cache or if it has to retrieve the change file from the server.
Sure enough, after touching the file the server sends a new change-ID, i.e. 17002 after the first touch and then 17003 after the second touch. As expected, the file-ID doesn't change.
Why does the client issues two GETTATTR requests? The first is for
the directory the file is located in (NF4DIR).
Closing Remarks¶
So when does the VM caching matter? Or, how can accidentally work against this mechanism when using NFS?
Say, entirely hypothetical, you have a compute cluster where typical compute jobs are actually program chains where the output of one program is the input of the next one. Also assume that the working directories are shared via NFS for flexibility and redundancy. For example, when one cluster node crashes in the middle of a chain then the chain can be completed on another node without having to recompute everything.
In that scenario, the best case would be: the complete chain is executed on one cluster node. A job-scheduler only schedules the complete chain to a cluster node. It doesn't re-schedule single programs of a chain between cluster nodes. Then the input for the program next in chain comes from VM subsystem and doesn't need to be transmitted over the network.
In contrast to that, since the work directories are shared, it is also possible to have finer job scheduling granularity, i.e. for each program of a chain. But this would increase the load on the NFS server. In the worst-case the NFS server's outgoing network traffic would multiply because the result of one chain program executed on cluster node A would have to be retrieved from the NFS server by the next chain program executed on cluster node B.
Similar reasoning applies to other network filesystems (and other operating systems with a VM subsystem) and thus it makes sense to build a chain-to-node-affinity mechanism into the job scheduler such that the VM cache re-use is maximized in such a chain-job environment.